
Data onboarding process
Lexer offers a wide range of tools to get data into the CDP, from our amazing Shopify integration, through to highly customizable apis for Bulk Uploads. Understanding the data ingestion process is really important for anyone uploading data to the CDP, and it’s even more important when handling more complex use cases such as our Bulk Write API. In this article we’ll run through all you need to know to understand this process which will make our Datasets, Logs and Healthchecks features an absolute powerhouse to monitor your data.
For more information about these tools check out the links below:
Ingestion overview
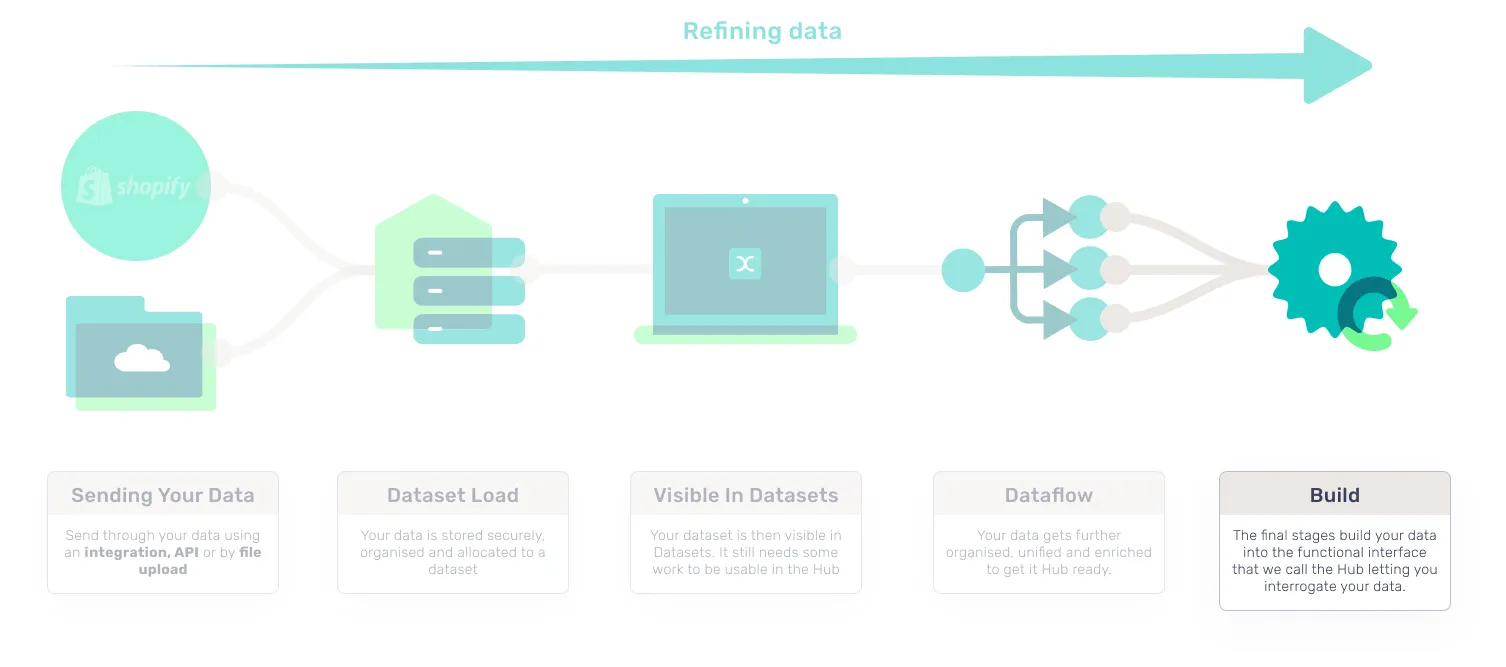
First things first, you need to understand the jobs that consume your data into the Hub. These jobs are independent and happen in a specific order which makes understanding the process really helpful if you need to troubleshoot. The process shown is staggered.
Let’s take a look at how data is consumed into the Hub.

- Integration or File Upload sends data: Data is provided via integration or upload.
- Dataset load: A dataset loads that file and begins to organize the data.
- Visible in datasets: The dataset is then visible in Datasets (but the data hasn’t finished its journey yet).
- Dataflow: Your data then goes through multiple processes that organize and enrich your data to get it CDP ready.
- Build: The final stages build your data into the functional interface that we call the Hub letting you interrogate your data.
Your data is now available to use in the Hub.
Let’s dive a little deeper
1. Sending your data
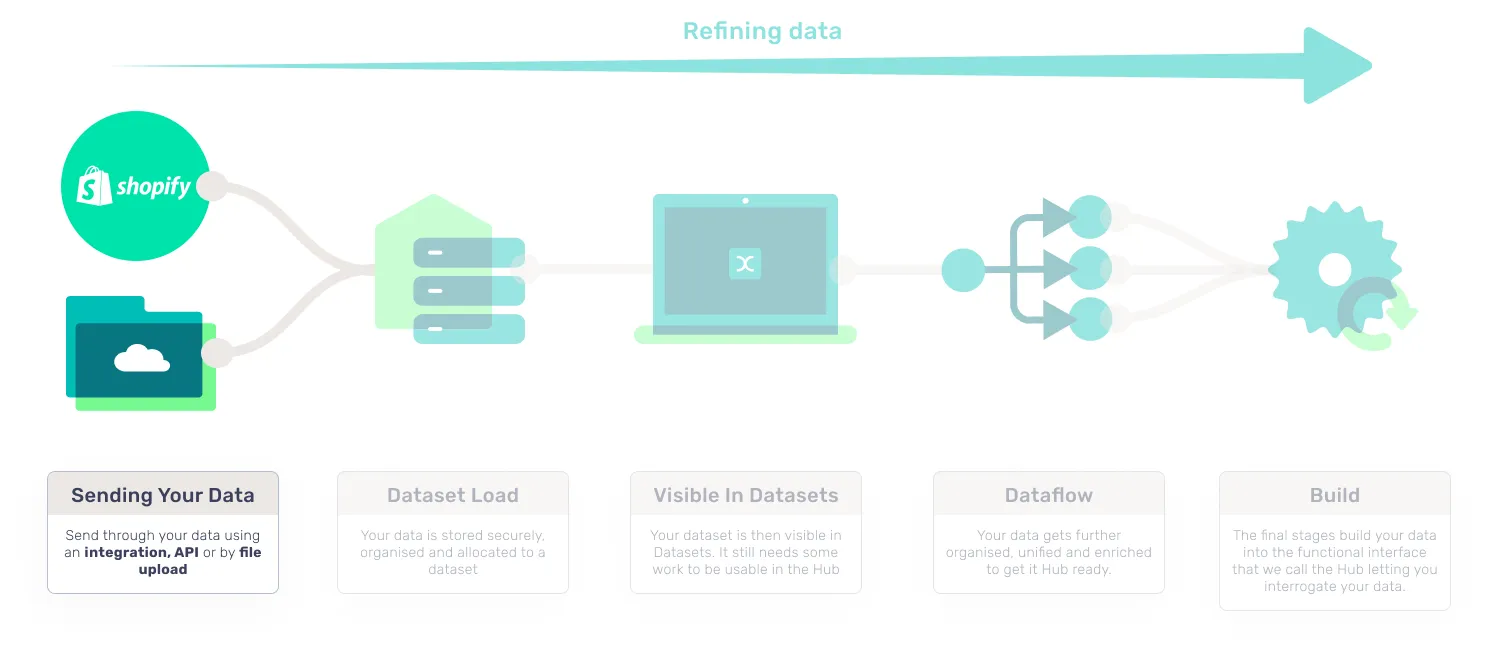
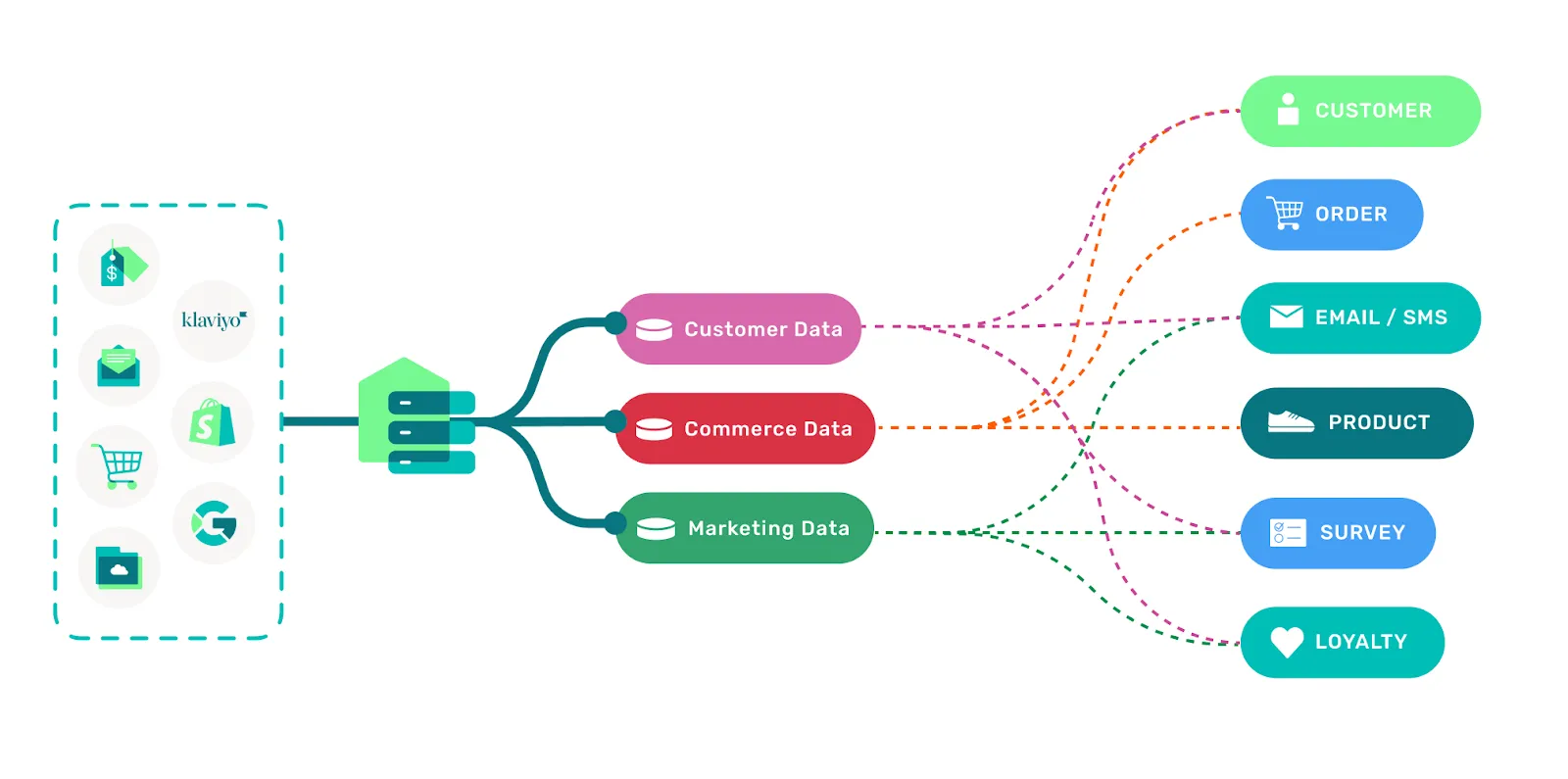
There are all sorts of different types of data that can be consumed by the CDP. These different types serve different purposes and are analyzed in different ways. They fall into 3 main categories: Customer, Commerce and Marketing data, however you can also talk to your Success Manager about Custom data too. Within each type, there are record types that further distinguish the data being consumed.
The main categories we use to differentiate this data are shown below:
- Customer data: customer_record
- Commerce data: product, purchase, return
- Marketing data: email_subscribe, email_send, email_open, email_click, email_bounce, sms_subscribe, sms_send, sms_click
- Custom data: reach out to your Success Manager to discuss uploading custom data that doesn’t conform to our integrations or schemas.
This data can be sent in a number of different ways, from simply integrating with an established integration (you can find the list of our integrations here), all the way through to our Bulk write API that allows you to send through JSON files containing your data. To figure out the best option for you it's always best to discuss your ingestion strategy with your Success Manager as different use cases need different strategies. There are some suggestions for troubleshooting at the end of this page.
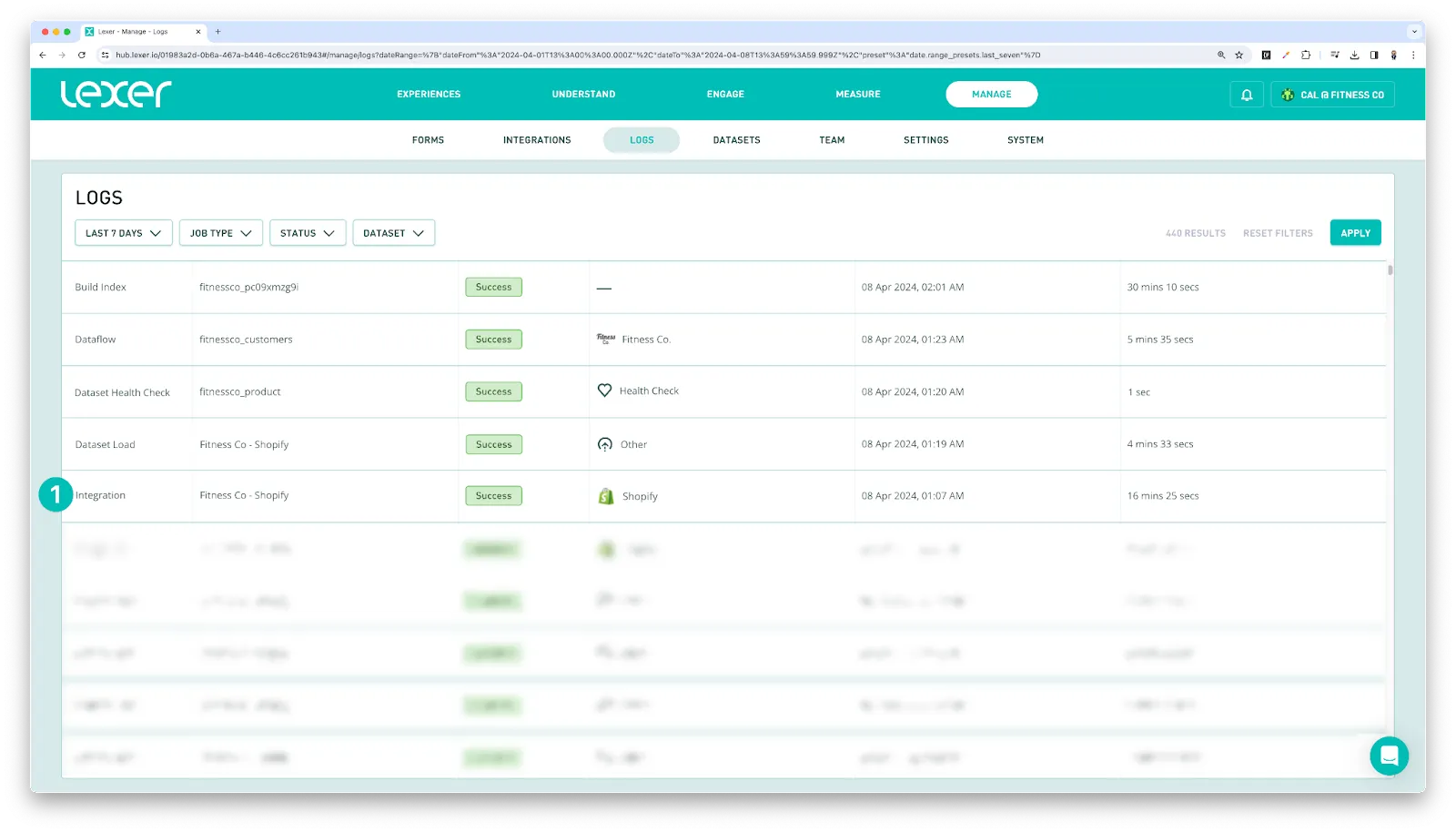
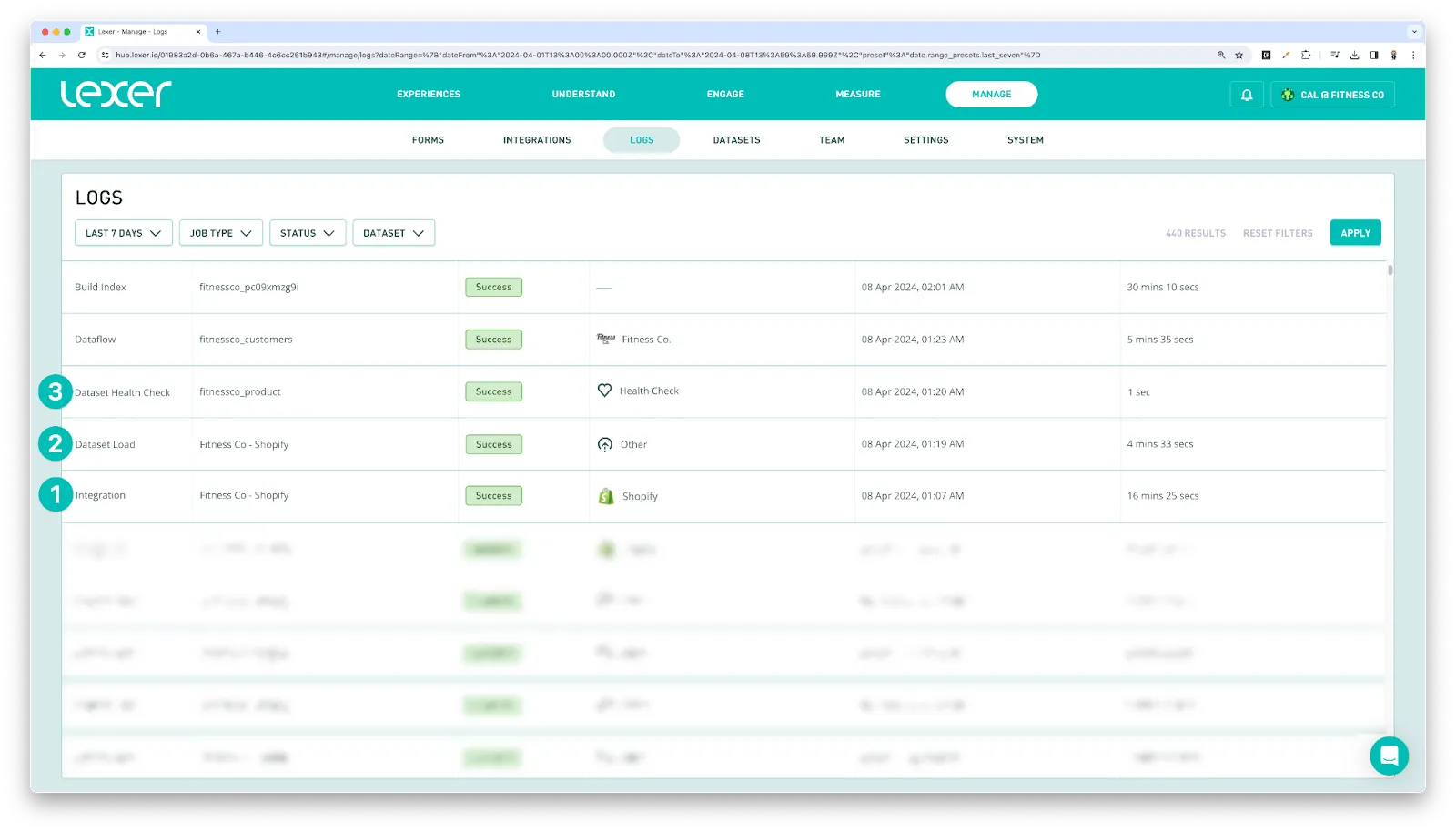
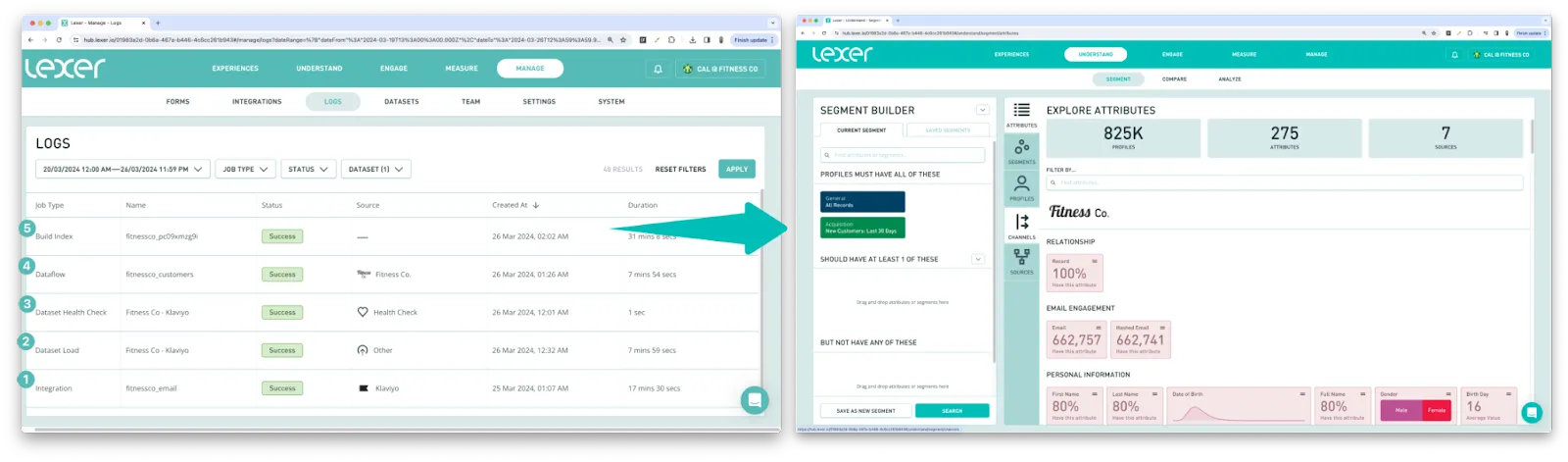
Once complete, you should see a job reflecting this in Logs. A File upload or Integration job depending on the method you have chosen.
2. Dataset load
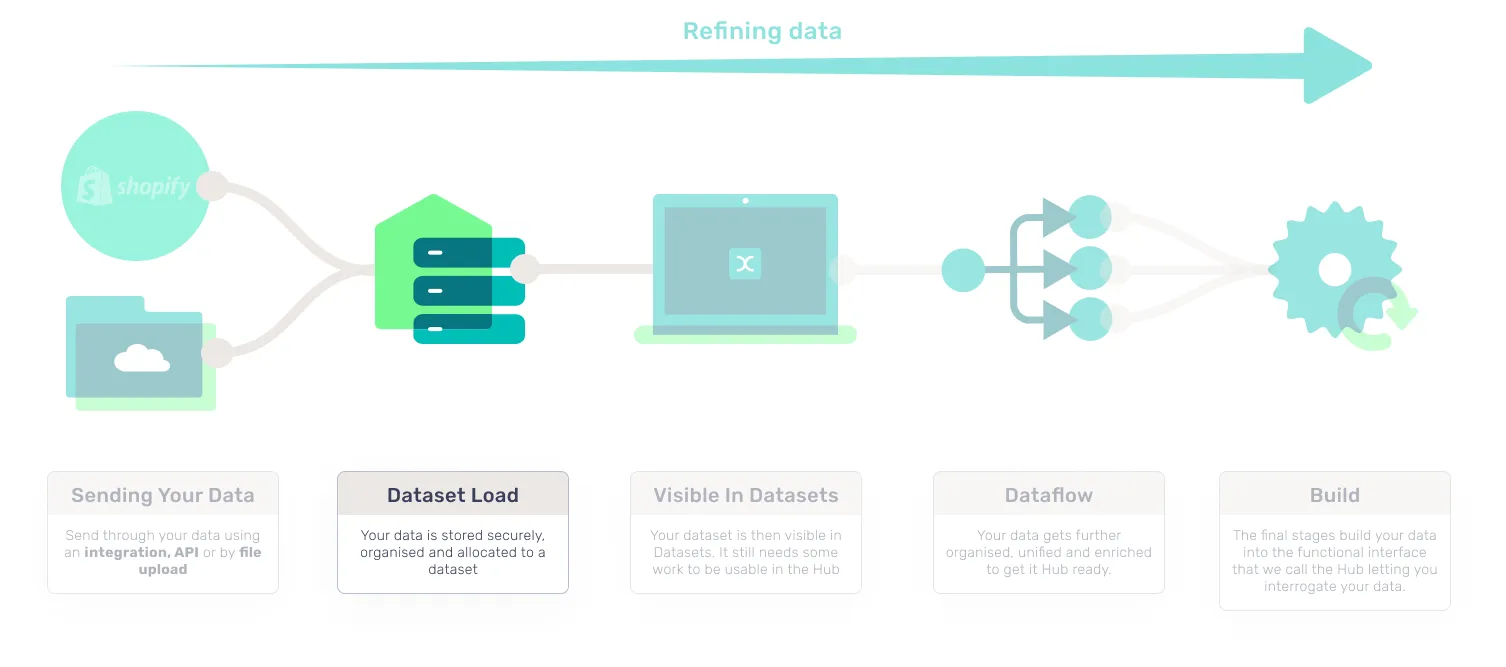
At this stage we make sure the data is valid, and conforms to our data specification requirements. Our integrations make this super simple as we have a predefined structure in place, you integrate your accounts and let the CDP take care of the data transfer.
For the more bespoke solutions where you are sending in files for processing, these get sent to Lexer’s secure storage. From here, if they are in the correct format, they are then able to be consumed into a dataset in the CDP.

If the data is clean, valid and matches the required format, you should see a Dataset Load job reflecting this in Logs.
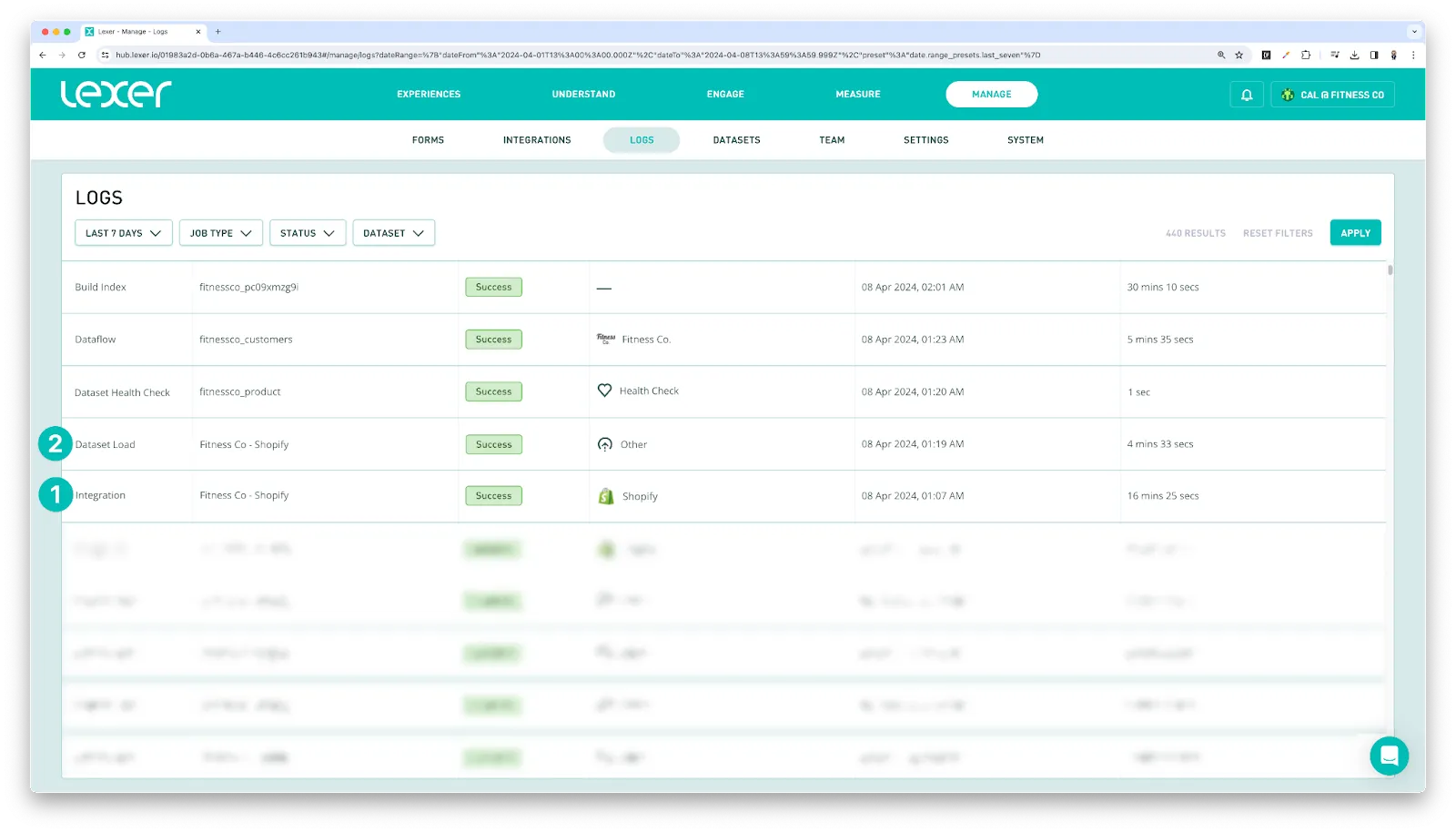
If you notice a problem, reach out to Support as soon as possible to try to identify the issue.
3. Visible in datasets
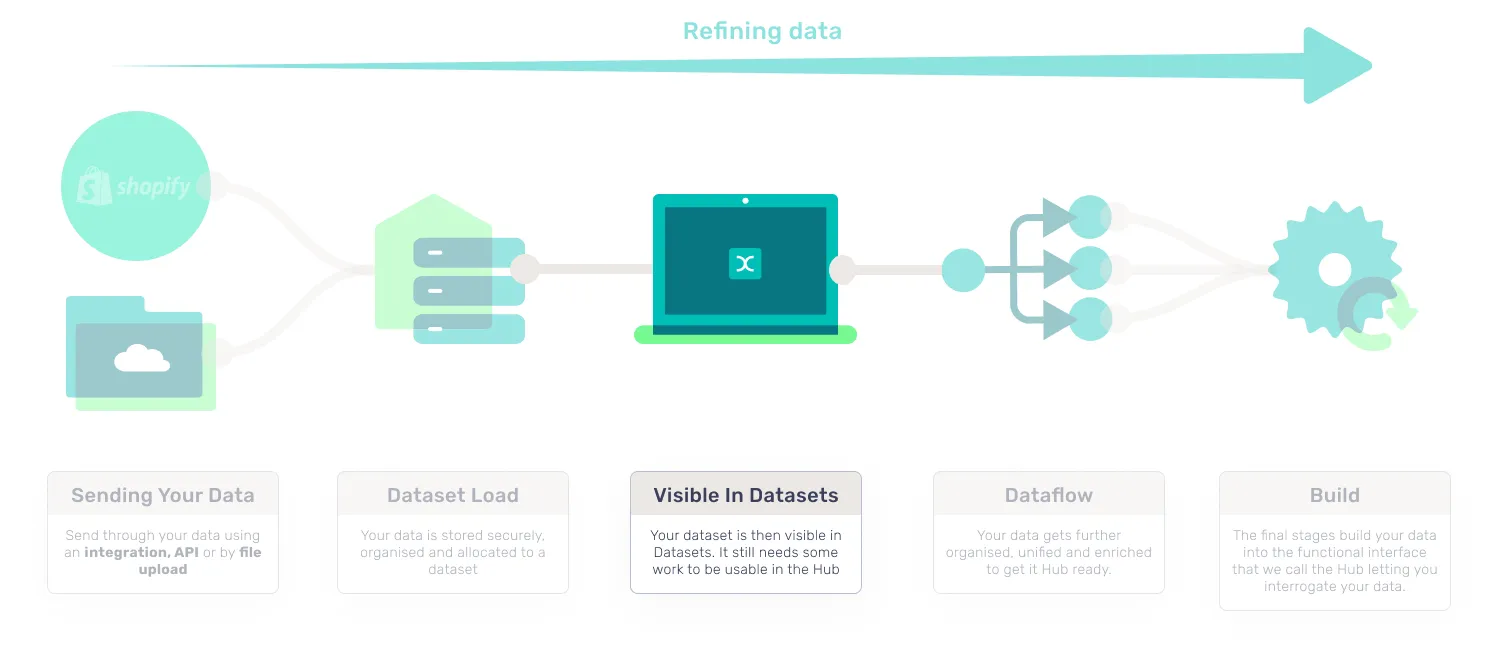
At this stage your data can be viewed in Datasets. In the scenario where the Dataset Load fails, the dataset will be empty and you will need to go back to step two, or contact Support for help. If anything goes wrong with the load you will notice the dataset will not have received your data. At this point you will need to check what went wrong in Logs or reach out to your Success Manager for assistance identifying the problem.
Once your data is in Datasets, you have successfully uploaded your data. This doesn’t mean your data is in the CDP yet, but it does mean we have received what you have sent, which is a fantastic starting point. From here your data will be processed further.
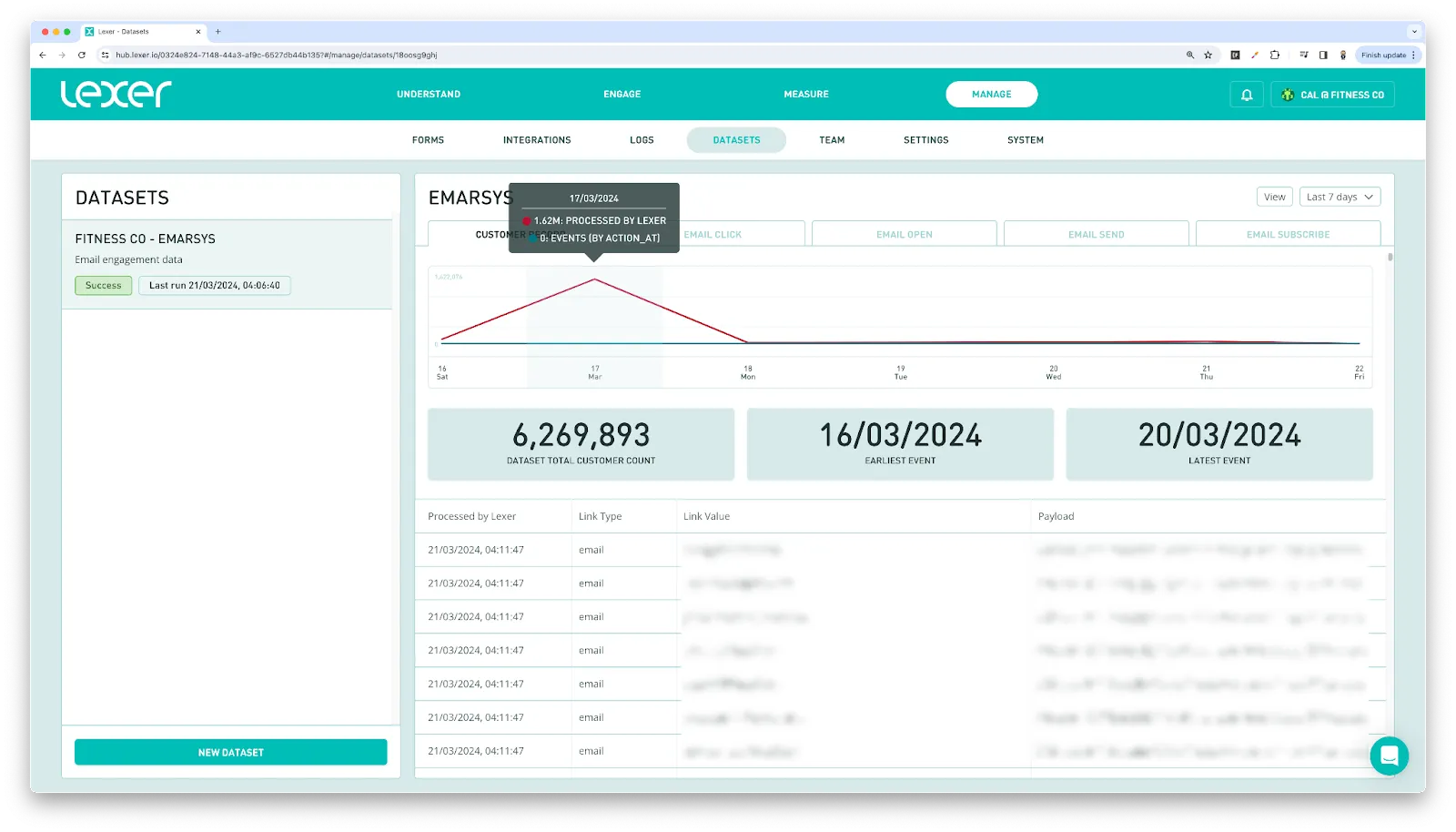
At this stage Health checks will begin to run on your dataset. Health checks can take up to 24 hours to run.
For more information about Datasets, check out our Dataset management article.
4. Dataflow
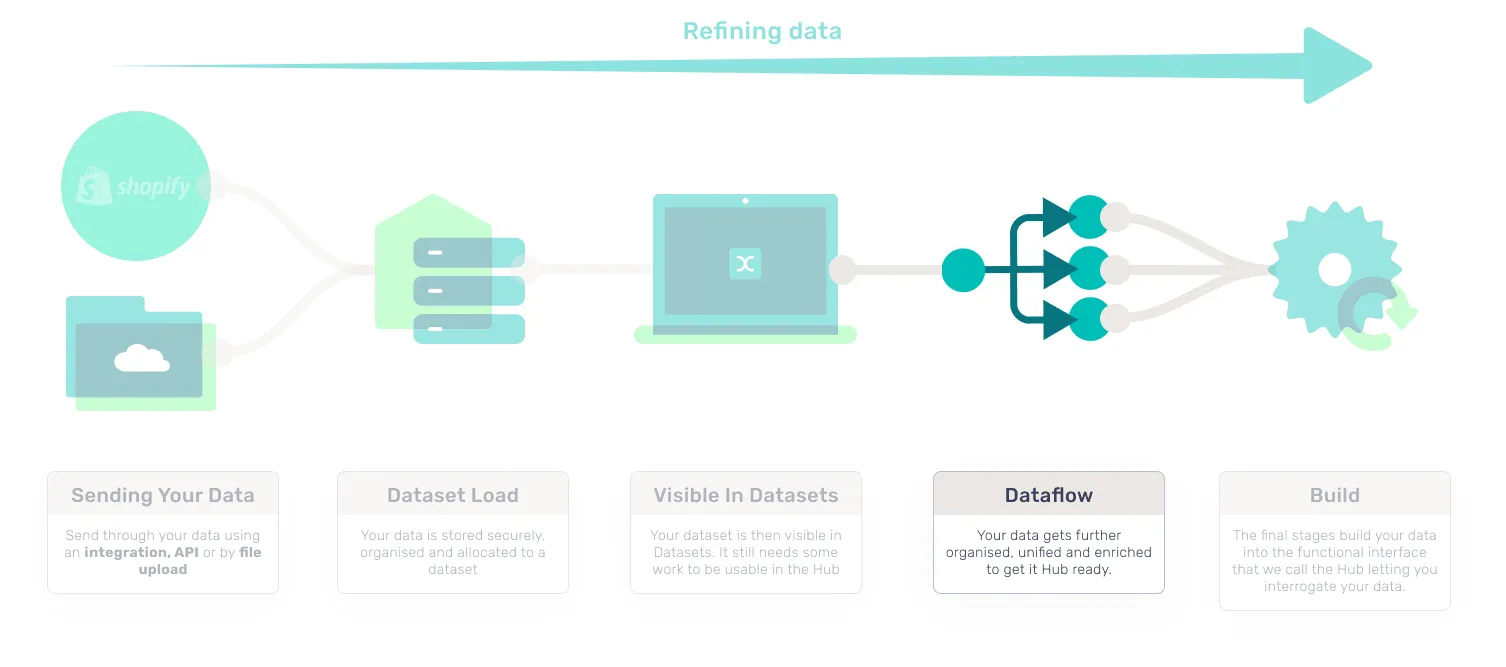
The Dataflow stage is where enrichment occurs bringing together all of the disparate data that you’ve sent from a multitude of different sources. The data is siphoned into the different channels that allow the CDP to accurately organize and enrich it for use in the Hub. At this stage the data begins to be transformed. Once all of the data has been effectively distributed, this data can pass through to the final stages of the ingestion process.
Once complete, you should see a Dataflow job reflecting this in Logs.

5. Build - The final job
The final job is where the magic happens. The CDP collates all of your data into your Hub allowing you to interrogate and manipulate this into actionable insights. Part of this job involves unification, where all the different bits of data for each customer is brought together into a single unified profile.
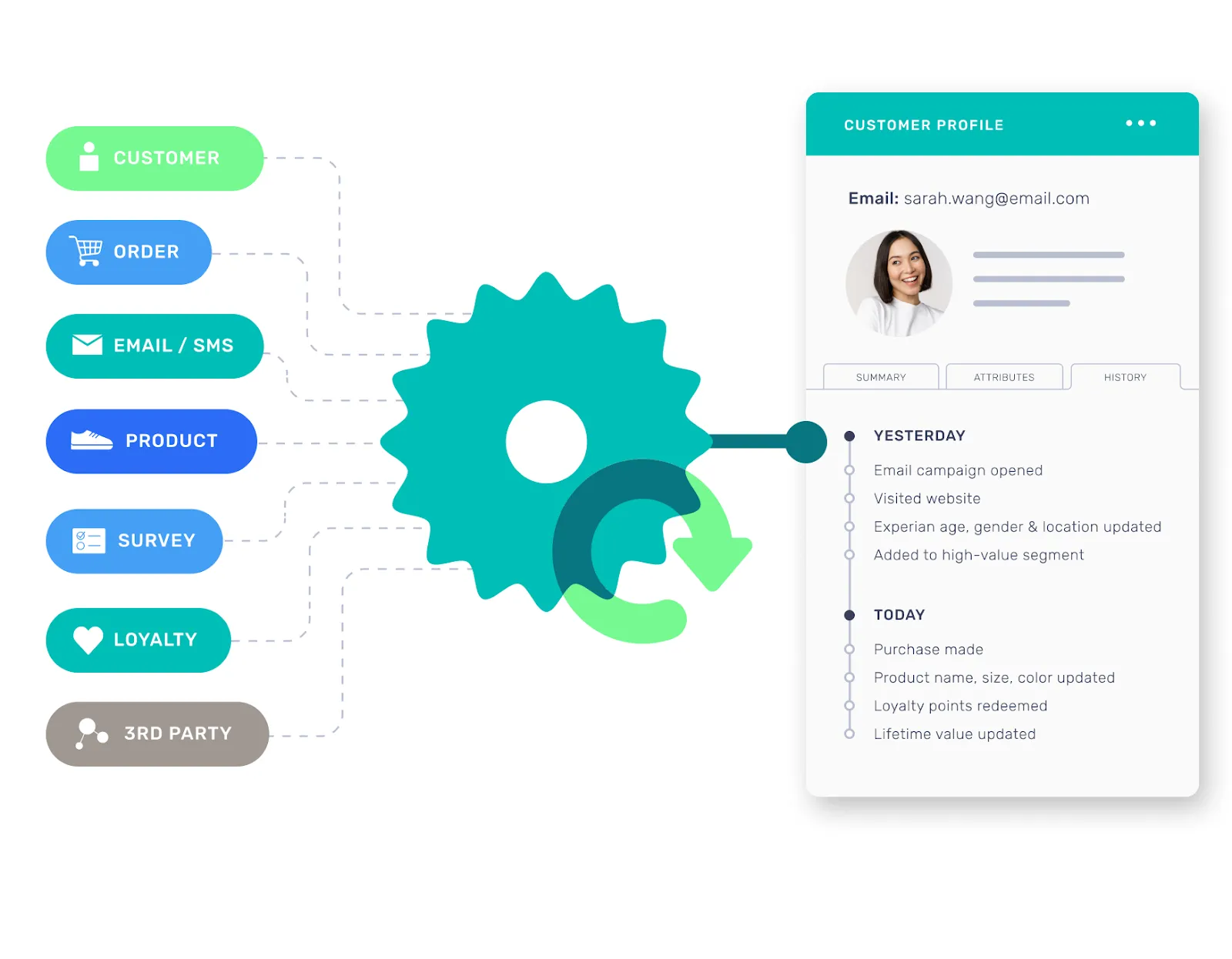
You can find more information about unification here.
The build occurs on a schedule consolidating and finalizing all of the adjustments made throughout the entire ingestion process. Once these steps are complete, you’ll see a final job take place in logs, the “Build index”. Once this is visible in Logs, your data is officially in the Hub and ready to use!
Troubleshooting
Troubleshooting uploads
If you run into any difficulties during data upload, Lexer may be unable to access your data, which can increase the importance of troubleshooting.
If this happens it is best to be proactive.
- Check out the relevant Learn content to help you troubleshoot the ingestion process you are carrying out.
Some Learn materials that might help:
- Integration guides
- Understanding APls at Lexer
- Providing JSON data to Lexer
- Providing CSV data to Lexer
- Upload using SFTP
- Upload using S3
- If this doesn’t rectify the problem, or you have a bespoke use case that might require custom work, reach out to your Success Manager or Support as soon as possible to try to identify the issue.
To recap
When your data is ingested, it goes through a 5 stage process before you can use it in the hub. The stages of the process are:
- Integration or File Upload: You integrate or upload a file.
- Dataset Load: The uploaded data is loaded into a dataset, beginning data organization.
- Visible in Datasets: The dataset appears in Datasets, signaling the initial stage of data processing.
- Dataflow: Your data goes through multiple processes to organize and enrich it for Hub readiness.
- Build: The final stages involve building your data into the functional Hub interface, enabling interrogation.
Your data is now available in the Hub and ready to use.
That’s a wrap!
In this article, we have covered the process all data goes through when it is ingested into the Hub. We looked through how this data is reflected in the Hub as it progresses through ingestion. We’ve linked out to a bunch of Learn articles to help guide you through the ingestion process. If you are still having trouble, please reach out to Support using the link in the bottom right of the page.
